Bert : Multi Label Text Classification Using Bert The Mighty Transformer By Kaushal Trivedi Huggingface Medium

Smaller BERT Models This is a release of 24 smaller BERT models English only uncased trained with WordPiece masking referenced in Well-Read Students Learn Better. BERT is a model with absolute position embeddings so its usually advised to pad the inputs on the right rather than the left.

Bert Explained A List Of Frequently Asked Questions Let The Machines Learn
BERT was trained with the masked language modeling MLM and next sentence prediction NSP objectives.
Bert. Bert was originally performed by Frank Oz. BOBB will allow you 247 access to your BERT and CIP accounts. BOBB makes updating your personal details checking your balance and payments and submitting enquiries easy.
It is efficient at predicting masked tokens and at NLU in. We have shown that the standard BERT recipe including model architecture and training objective is effective on a wide range of model. Our Employers Online system allows employers.
Bert is a yellow Muppet character on the long running PBS and HBO childrens television show Sesame Street. BERT是截至2018年10月的最新state of the art模型通过预训练和精调横扫了11项NLP任务这首先就是最大的优点了. BERTは登場してまだ1年半程度であるにもかかわらず被引用数は2020年5月4日現在で4809 にも及びます驚異的ですこの記事ではそんなBERTの論文を徹底的に解説していきたいと思いますBERTの理解にはTransformerVaswani A.
Then uncompress the zip file. A transformer architecture is an encoder-decoder network that uses self-attention on the encoder side and attention on the decoder side. 데이터들을 임베딩하여 훈련시킬 데이터를 모두 인코딩 하였으면.
Also since running BERT is a GPU intensive task Id suggest installing the bert-serving-server on a cloud-based GPU or some other machine that has high compute capacity. Bert Karlsson Marcus Persson. As a result the pre-trained BERT model can be fine-tuned.
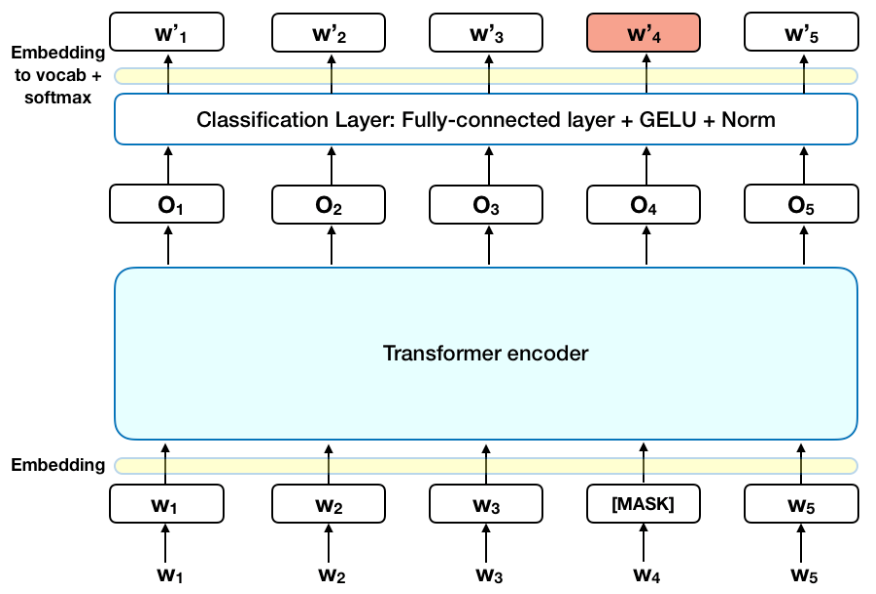
On the Importance of Pre-training Compact Models. BERT BASE has 1 2 layers in the Encoder stack while BERT LARGE has 24 layers in the Encoder stack. For BERT models from the drop-down above the preprocessing model is selected automatically.
In contrast to the practical-joking extroverted Ernie Bert is serious studious and tries to make sense of his friends actions. Now go back to your terminal and download a model listed below. It has caused a stir in the Machine Learning community by presenting state-of-the-art results in a wide variety of NLP tasks including Question Answering SQuAD v11 Natural Language Inference MNLI and others.
Bert is Ernies best friend and roommate on Sesame Street. This is the preferred API to load a TF2-style SavedModel from TF Hub into a Keras model. BERT New March 11th 2020.
Making BERT Work for You The models that we are releasing can be fine-tuned on a wide variety of NLP tasks in a few hours or less. 이를 스스로 라벨을 만들고 준지도학습을 수행하였다고 합니다. The open source release also includes code to run pre-training although we believe the majority of NLP researchers who use BERT will never need to.
We introduce a new language representation model called BERT which stands for Bidirectional Encoder Representations from Transformers. BERT Bidirectional Encoder Representations from Transformers is a recent paper published by researchers at Google AI Language. His own passions include reading Boring Stories collecting paper clips and bottle caps especially the rare Figgy Fizz consuming oatmeal and.
Unlike recent language representation models BERT is designed to pre-train deep bidirectional representations from unlabeled text by jointly conditioning on both left and right context in all layers. BOBB - Your BERT Online Balances Benefits. It will provide you with the most up to date information on your account.
The pair share the basement apartment at 123 Sesame Street. You will load the preprocessing model into a hubKerasLayer to compose your fine-tuned model. Since 1997 Muppeteer Eric Jacobson has been phased in as Berts primary performer.
Bert has also made cameo appearances within The Muppets franchise including The Muppet Show The Muppet Movie. BERT is basically an Encoder stack of transformer architecture. Berts Värld - Djupdykningar i samhällsfrågor ocensurerat och rakt på med Bert KarlssonAnsvariga utgivare.
BERT는 이미 총33억 단어 BookCorpus Wikipedia Data의 거대한 코퍼스를 정제하고 임베딩하여 학습시킨 모델입니다.

Squeezie Herr Bert Fur S Oktoberfest

Instrumente Entdecken Mit Ernie Und Bert Ndr De Orchester Und Chor Ndr Radiophilharmonie Junge Rph

Bert Explained A Complete Guide With Theory And Tutorial Towards Machine Learning

Sind Ernie Und Bert Schwul Das Sagt Der Autor Der Sesamtrasse Stern De

Ernie Und Bert Sind Ein Paar Computer Bild

Bert Bertsesame Twitter

Bert How Google Changed Nlp Codemotion Magazine

German Bert State Of The Art Language Model For German Nlp

How To Fine Tune Bert Transformer Python Towards Data Science
Bert Explained State Of The Art Language Model For Nlp By Rani Horev Towards Data Science

Sesamstrasse Ernie Und Bert Sind Fur Serienschreiber Ein Schwules Paar Der Spiegel

Nici Sesamstrasse Kuscheltier Bert 35 Cm Schlenker 43508 Babymarkt De

Joy Toy T75364 Bert 35 Cm Sesamstrasse Amazon De Spielzeug

Multi Label Text Classification Using Bert The Mighty Transformer By Kaushal Trivedi Huggingface Medium

Plush Doll Bert Ernie Und Bert Sesame Street Products Nici Online Shop
Bert Waldau Lidl In Deutschland Linkedin


Ernie Und Bert Sind Die Sesamstrasse Figuren Nun Schwul Oder Nicht Der Spiegel

Bert Muppet Wiki Fandom

Bert Spahn Bertspahn Twitter
Post a Comment
Post a Comment